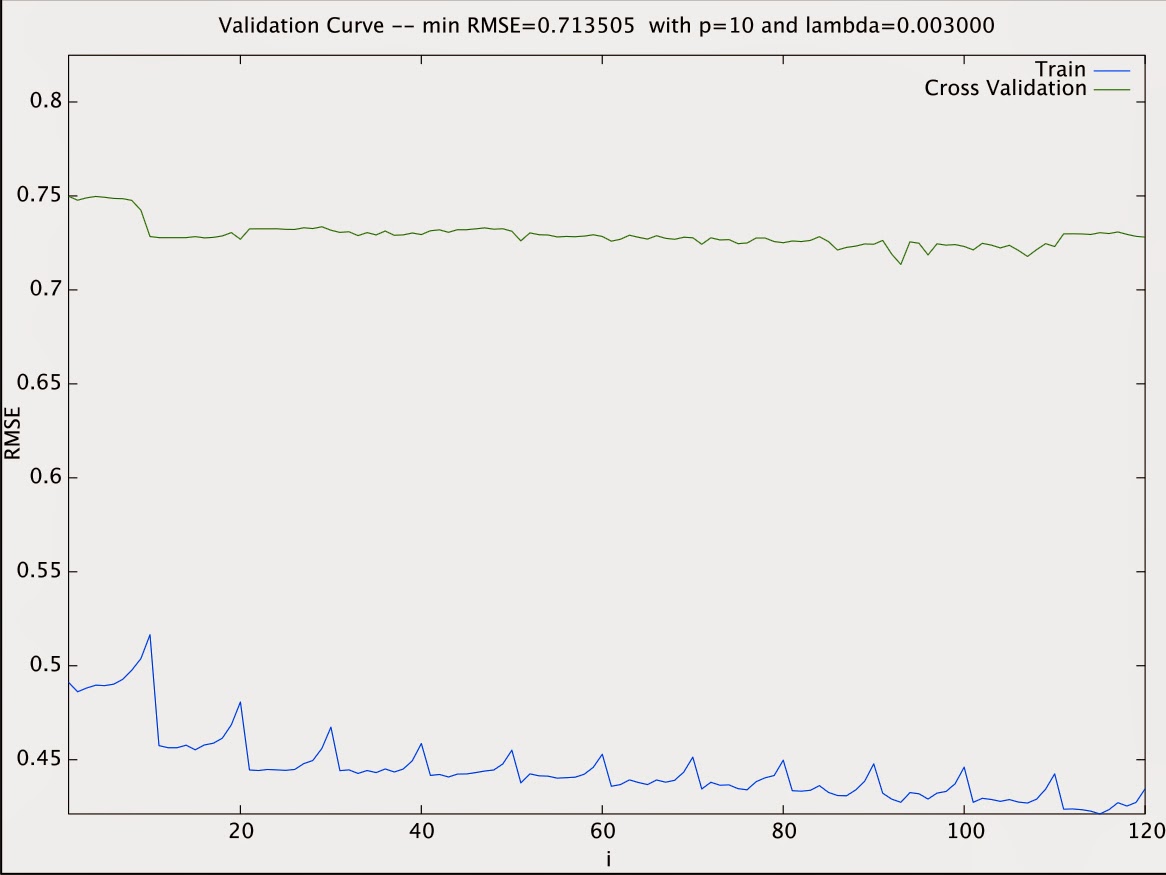
There's no yet the function
paint(as.van.gogh(..),..) , but it's already possibile to get a beautiful paint in Van Gogh style training no less than 150 models (perhaps, after 20/30 hours computing) with the same sampling algorithm and painting resampling results across models where each line corresponds to a common cross-validation holdout (aka
parallelplot).
Why doing that? ... that's another story ... anyway, I find the use of red a bit excessive, so we can sell it as a Van Gogh of earlier years. Very important, there're no correlation with the problem, as results don't change.
And what about a Matisse? ...same information can be presented with
dotplot ... and results don't delude.